Many of us use AI tools every day and gain good individual productivity wins. But scaling that into enterprise use cases? That’s when those tough conversations about data quality begin, and so many leaders get stuck in data limbo: unable to move forward and blaming the quality of their data. To break out, you must be honest about your problems.
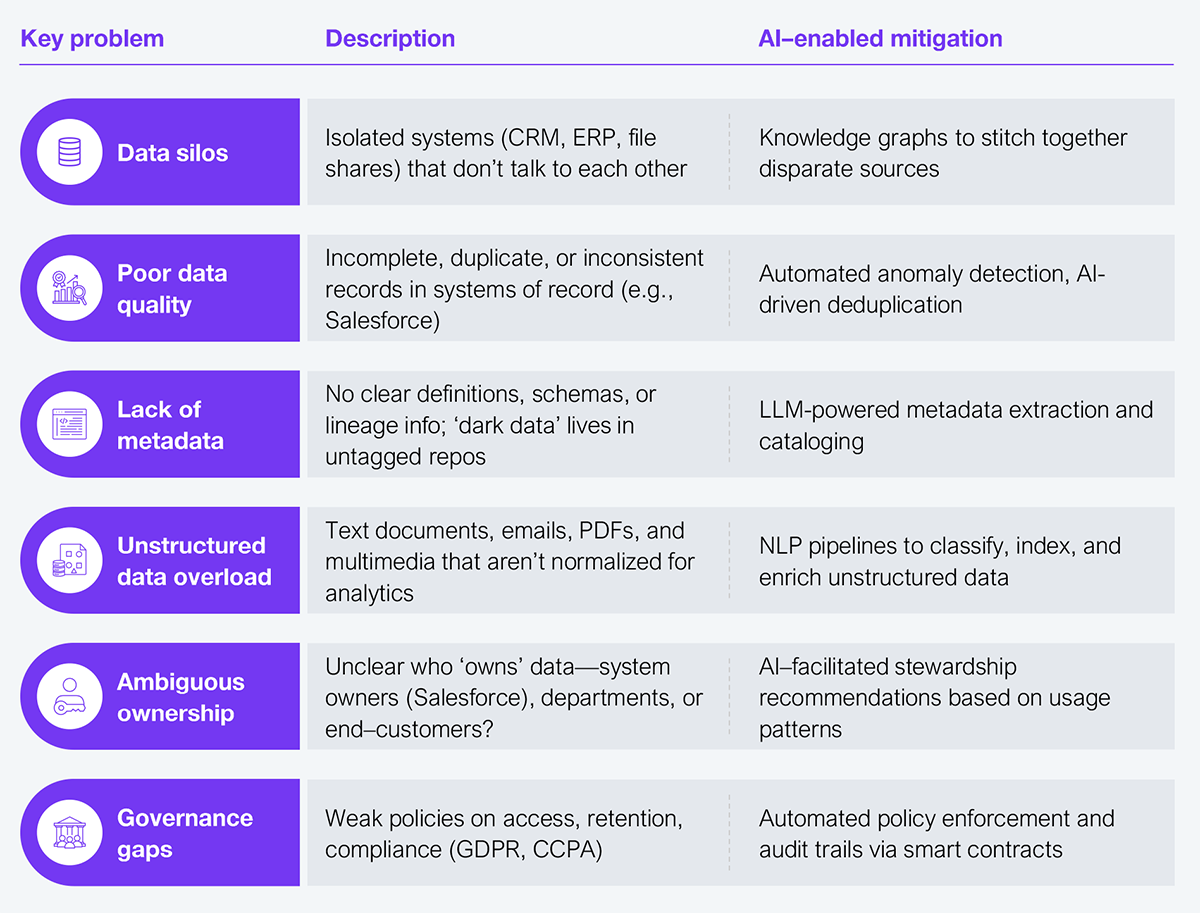
This starts by getting into the nitty-gritty of what we really mean when we say we don’t have the ‘right’ data to succeed with AI or that it’s siloed, incomplete, or messy. Our chart (see Exhibit 1) dives in to offer clarity. Recognizing the problems you face is important if you are going to solve them and make the journey from ‘bad data’ to AI-driven value.
Source: HFS Research, 2025
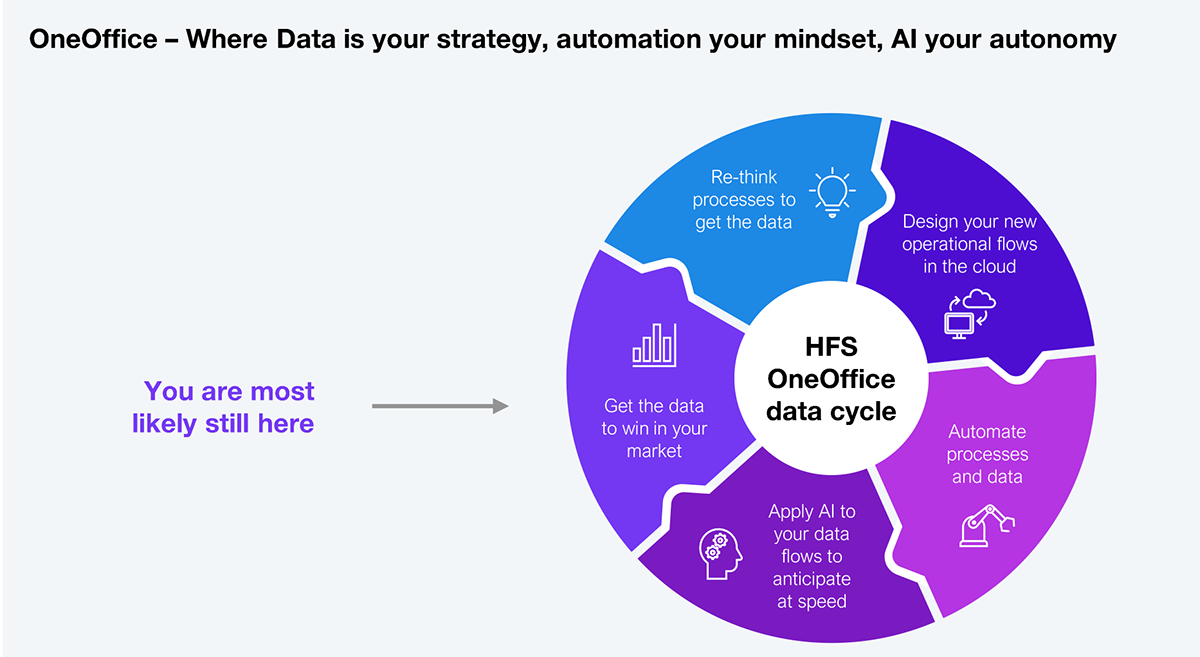
OneOffice is HFS Research’s enterprise model that breaks down traditional silos between front, middle, and back offices to create a single, digital, customer-centric enterprise. It’s where automation, AI, and data converge to create real-time workflows between customers, employees, and partners, without handoffs or latency (see Exhibit 2).
A OneOffice model creates an intelligent enterprise that operates in real-time, adapts to change, and delivers seamless customer experiences. Data is the lifeblood of OneOffice: it fuels decision-making, powers AI models, and ensures every function is aligned with customer and business outcomes.
Source: HFS Research, 2025
On average, barely a third of G2000 enterprise leaders are satisfied with the quality of their enterprise data (HFS survey, 2024—as detailed in this recent Horses for Sources blog post: How Generative and Agentic AI are Supercharging the OneOffice Data Cycle). The majority are still scratching their heads about how to get the data to win in their market—stuck in the data limbo of step one on the cycle.
The six challenges we outline below are barriers to your success. Know them, understand them, and apply AI to overcome them, and you’ll soon set the data cycle spinning to generate wins. Don’t expect this to be easy. Legacy systems may not expose clean metadata or APIs. AI cleansing will have to be transparently explained, to take people (and regulators) with you, and you’ll need scarce data engineers and AI-ops talent to maintain pipelines. If you are prepared for that journey, let’s get rolling:
1. Data silos
Problem: Sales, finance, HR, and support run on different platforms. Systems such as CRM, ERP, and file shares often don’t talk to each other. You can’t build an ‘agentic AI’ that orchestrates processes end-to-end without a unified view, and while ETL (extract-transform-load) and APIs have been around for decades, adoption still lags.
2. Poor data quality
Problem: Your data is incomplete, full of duplicates, and inconsistencies, or has contradictory fields, e.g., missing country codes or duplicated customer IDs. Data quality tools such as Master Data Management (MDM) are old guard, expensive, and slow to implement.
3. Lack of metadata
Problem: No provenance—teams don’t know where the data originated or how it’s transformed. It lacks definitions, schemas, or lineage, resulting in ‘dark data’ in untagged repositories. The old-school fix was manual documentation and governance councils—both bureaucratic and slow.
4. Unstructured data overload
Problem: 80% of enterprise data lives in emails, documents, and recordings; and they aren’t analytics ready. Traditionally, that required keyword indexing and manual tagging—which is highly labor-intensive.
5. Ambiguous data ownership
Problem: Who ‘owns’ the canonical record? Salesforce admin? Finance? The end customer? The result of such confusion is no clear accountability for data across systems and finger-pointing slows decision-making as clashes over governance rumble on.
6. Governance gaps
Problem: GDPR, CCPA, and internal security policies often clash with rapid data usage. The solutions to date have been compliance checklists and manual reviews, and these are prone to error.
Recognize the problems you face to solve the data debt challenges that will set you moving around the HFS OneOffice Data Cycle. Tackling these is hard but with the emergence of AI tools to help, it is now doable.
You will need persistence and patience to reap the rewards, but you can no longer hide behind the excuse that the challenge is too great to tackle during your tenure.
Register now for immediate access of HFS' research, data and forward looking trends.
Get StartedIf you don't have an account, Register here |
With the exception of our Horizons reports, most of our research is available for free on our website. Sign up for a free account and start realizing the power of insights now.
Our premium subscription gives enterprise clients access to our complete library of proprietary research, direct access to our industry analysts, and other benefits.
Contact us at [email protected] for more information on premium access.
If you are looking for help getting in touch with someone from HFS, please click the chat button to the bottom right of your screen to start a conversation with a member of our team.

