AI capabilities have become critical elements of business success for organizations in any industry—there is exponentially more data than humans can process, so algorithms must do the work. The algorithms must be well-trained and sophisticated, but a massive amount of training data is necessary to produce this end.
A growing number of tech firms are addressing this problem by providing enterprise clients with a simple solution: fake, or “synthetic,” data. These are data sets created by algorithms that are fed smaller real-world data samples, which the algorithms use to derive a set of rules for creating similar data points to train neural networks. This gives companies the option of buying ready-made, large data sets for less money than it would cost them to collect real-world samples at the same scale. Using synthetic data reduces the cost and time to market, thus breaking down one of the biggest barriers to AI success plaguing companies today.
Synthetic data holds immense potential for many organizations struggling to stay competitive—both small start-ups competing against leading tech firms and legacy organizations not inherently equipped for a digital environment. However, even though synthetic data is not a new technology, in many ways, it’s still nascent. To reap synthetic data’s rewards, companies must navigate several obstacles and consider many factors, including model quality and exception handling risks. But the fact remains that there are now many options available for those companies willing to place their bets on artificial data, and able to navigate its risks.
Synthetic data eases painful data requirements
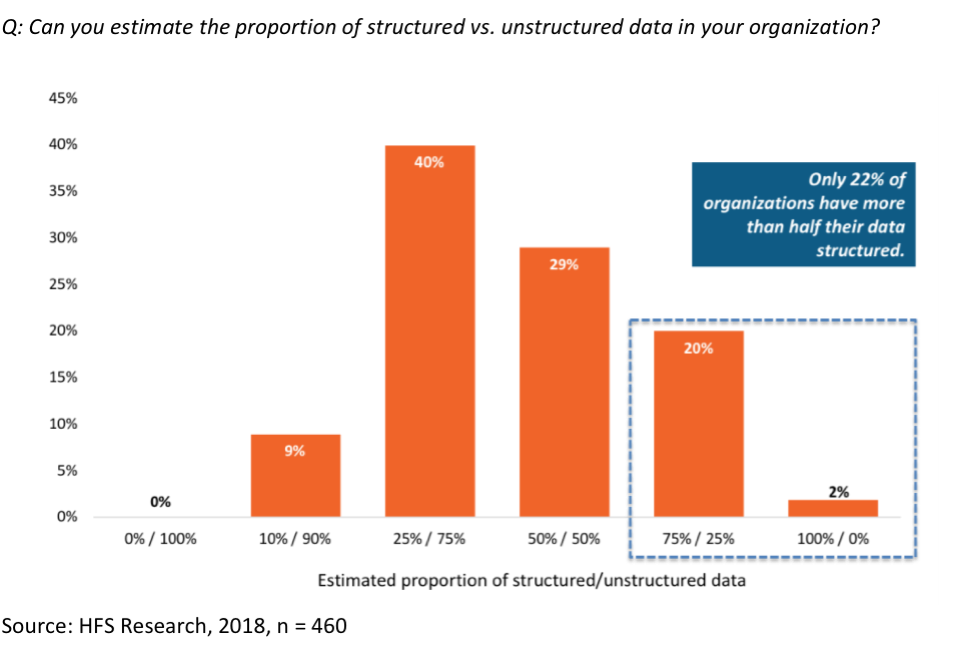
Deep learning is a form of AI in which non-linear algorithms crunch vast quantities of both structured and unstructured data without supervision to derive rules and patterns, which they then use to “learn” how to interpret similar data going forward. Deep learning and neural networks are currently the height of AI sophistication—and therefore a major competitive advantage for any company harnessing them—but they are extremely data hungry. This data gluttony creates a major obstacle to AI success for all but the biggest and richest tech behemoths like Google, Amazon, and Facebook, which have unmatched tech talent pools and the resources to train and retain them, and upskill them as technology evolves. Most small startups and legacy organizations don’t have the technical expertise, capacity, or resources to amass and label the data volumes necessary to train neural networks meaningfully, leaving them behind in the race to AI supremacy (see Exhibit 1).
Exhibit 1: The state of data in organizations
Pioneering startups are reinventing synthetic data
Synthetic data has existed at the borders of AI for over a decade, but companies haven’t trusted it to train AI systems to a degree of sophistication capable of dealing with real-world scenarios. Over the past few years, this perception has changed as advances in data labeling and modeling have started to bridge what Cornell Tech’s Serge Belongie calls the “simulation-to-reality gap.” Indeed, a recent MIT study showed that when two datasets—one real and one artificially made—were given to data scientists in a task, there was no statistically significant difference in outcomes 70% of the time.
Although using created (as opposed to collected) data to train neural networks may still somehow feel controversial or counter-intuitive, this synthetic data can replace the real deal—at least in some situations. Seeking to capitalize on this, a growing number of startups are now catering to data-hungry companies wishing to make the big leap in their AI strategies. Below, we look at four of these players:
As with any developing technology, there are advantages that set synthetic data ahead of previously available alternatives, but also potential drawbacks a company must keep in mind when deciding whether or not this is the route it wants to go down while moving into the AI space. We lay out some of the main pros and cons of using synthetic data to train algorithms in Exhibit 2.
Exhibit 2: Pros and cons of using synthetic data to train AI algorithms

Whether the risks still attached to using synthetic data outweigh the potential benefits ultimately depends on the nature of the company seeking to use it. Here are some considerations if your organization is debating whether or not to use synthetic data in its AI strategy. Companies that fit this profile might be in a good position to proceed:
But, there are two hard-and-fast rules that all companies should follow regarding synthetic data usage for algorithm training. The first is that no organization can afford to dismiss the concept out of hand, as synthetic data is not what it once was, and it promises cost savings that are not to be sniffed at. Moreover, the tech behemoths of the world, despite their vast data collection capabilities, are also beginning to eye the use of synthetic data, threatening to pull even further ahead of their more cash-strapped, legacy competitors. The second is that for those companies that do make the step to go fake, conservatism should be the starting point. In other words, an open mind and a play-it-safe mindset are prerequisites for synthetic data use.
Register now for immediate access of HFS' research, data and forward looking trends.
Get Started
If you don't have an account, Register here |
With the exception of our Horizons reports, most of our research is available for free on our website. Sign up for a free account and start realizing the power of insights now.
Our premium subscription gives enterprise clients access to our complete library of proprietary research, direct access to our industry analysts, and other benefits.
Contact us at [email protected] for more information on premium access.