Most vendor offerings are being mislabeled as ‘agentic AI’, creating unrealistic expectations around solutions that are technically ‘copilots’ or intelligent automation with a chat interface.
Let’s clarify the differences. Copilots are assistants confined to a single app or workflow, triggered by a user, with limited memory and no autonomous planning or open tool choice. AI agents are individual systems executing specific tasks with policies, telemetry, and rollback. Agentic AI refers to orchestrated, autonomous systems that coordinate multiple agents, maintain context, and adapt dynamically to achieve broader business outcomes. Agentic-washing is the gap between the level of AI bought and the level marketed. If a vendor’s AI can’t decompose goals, choose tools across systems, remember context, and recover from failure, they’re not selling agentic AI—they’re selling AI-assisted workflows.
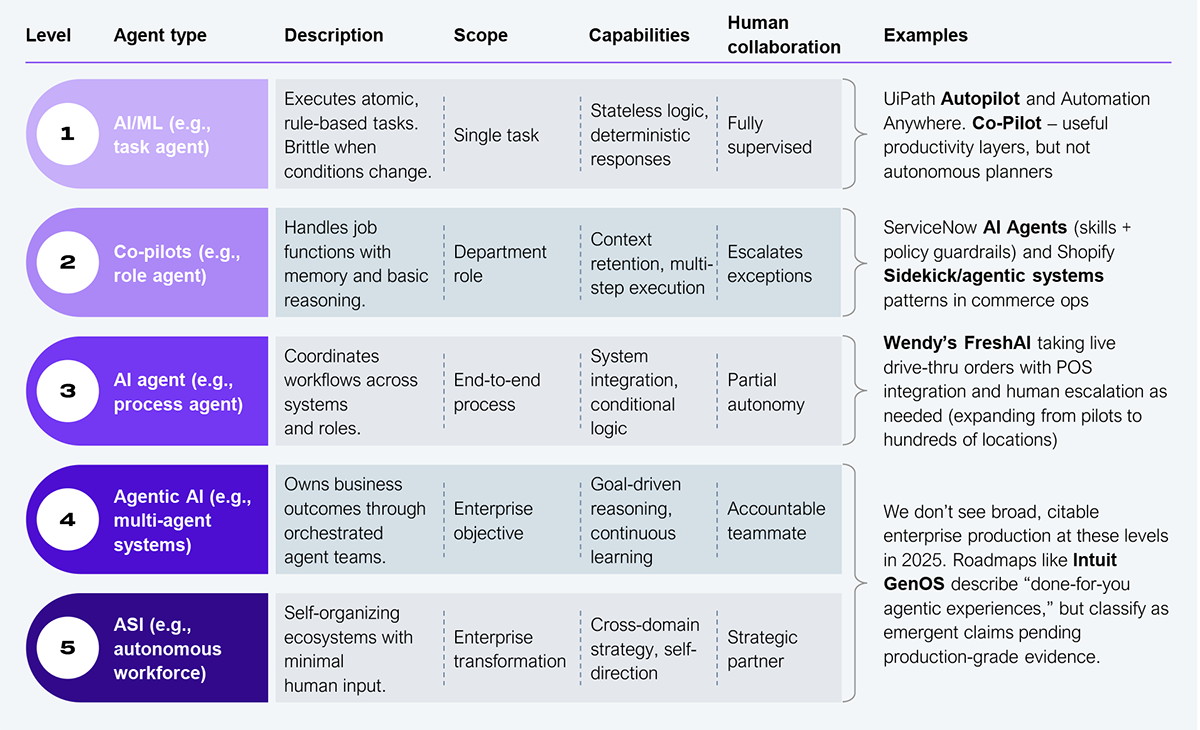
Vendors are rebadging copilots as ‘agents’ to imply autonomy and impact, yet most merely offer text to action inside existing workflows. You can spot it in the marketing: governance skills and chat commands inside an orchestrator, useful and deliberately bounded. Vendors should call these what they are: copilots. True enterprise-grade agentic AI is still rare, and what we see in the market reflects various maturity levels (see Exhibit 1).
Source: HFS Research, 2025
Most scaled deployments are Levels 1 and 2, and a smaller set reaches Level 3 in bounded domains. Levels 4 and 5, where agentic AI orchestrates across systems, remembers context, handles exceptions, improves with each run, and remains uncommon in production. Everything else is just automation with a fancy name. There’s a subtle difference between what ‘AI agents’ and ‘agentic AI’ mean, and they’re often thrown together without considering the nuance. That’s what moves the dial on mean time to resolution (MTTR), time-to-cash, and straight-through processing. For example, ServiceNow positions ‘AI Agents’ as a governed, skills‑based layer that interprets requests and orchestrates actions across IT/HR/service operations—powerful for ‘bounded autonomy,’ but the scope is defined by the skills and policies configured.
At the same time, automation vendors are rewrapping familiar capabilities to signal currency. Automation Anywhere’s Co‑Pilot lets business users create/run automations within the apps they use and helps automators turn natural language into bots. This leads to clear productivity wins, but it’s not the same as an agent that decomposes vague goals and selects tools dynamically. UiPath’s Autopilot is framed as ‘AI‑powered experiences’ for different personas; in practice, that means accelerated design, suggestions, and text‑to‑automation within the UiPath stack rather than open‑world autonomy. Systems integrators echo this shift: press releases tout portfolios of agentic AI operating at scale, but CIOs must demand evidence before calling it agentic.
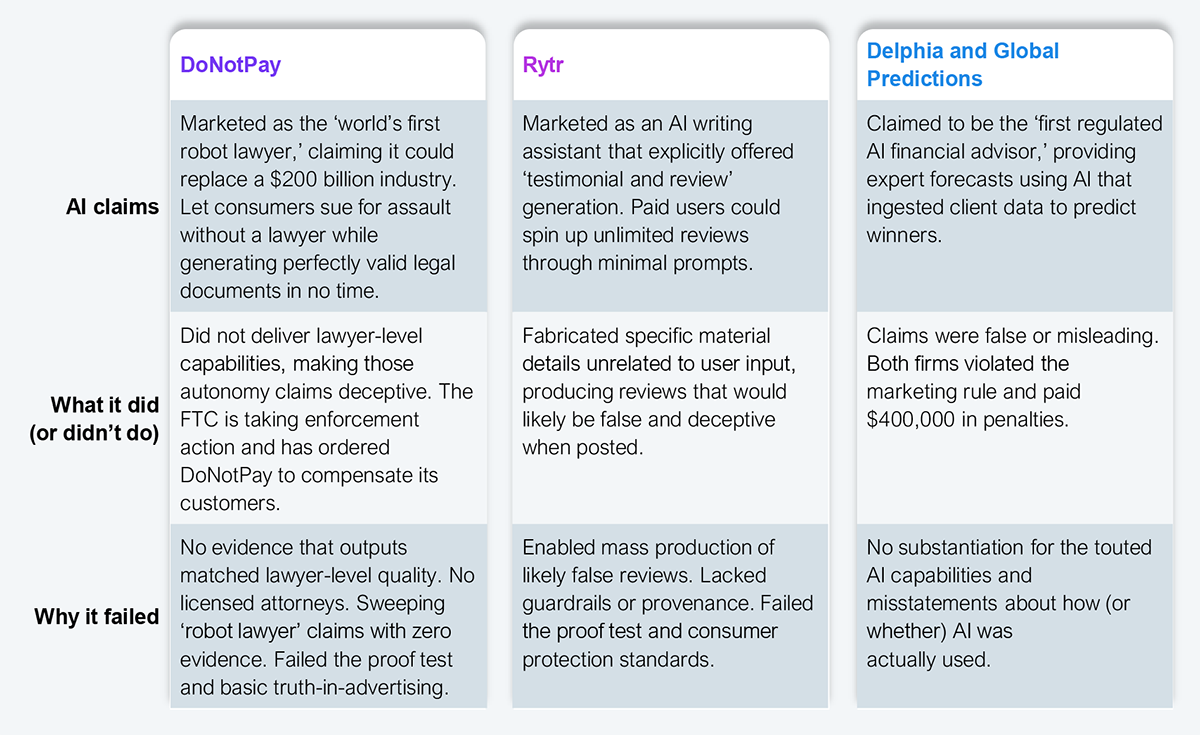
As AI becomes embedded deeper into enterprise workflows, claims about its capabilities become harder to verify and riskier to exaggerate. Authorities in the US and Europe are cracking down and enacting regulations around the business claims about AI-first products and solutions. The Council of Europe’s Framework Convention on AI is the first legally binding international treaty on AI (opened for signature Sept 5, 2024). It is tech-neutral and requires AI use across the lifecycle to align with human rights, democracy, and the rule of law. It introduces obligations around transparency, impact/risk assessment, and oversight, and allows states to set red lines. The FTC’s Operation AI Comply (announced Sept 25, 2024) is an enforcement sweep targeting deceptive AI claims; initial cases hit four companies and reinforced that the existing consumer-protection law already covers ‘AI-powered’ marketing. The message is clear: substantiate your claims with testing, logs, and outcomes, or expect actions.
Source: HFS Research, 2025
These cases set a precedent, and enterprises should take note: agentic-washing has real consequences, especially when it comes to autonomous AI/agentic systems. CIOs must demand verifiable proof—test results, audit logs, run traces—before accepting agentic AI claims at face value.
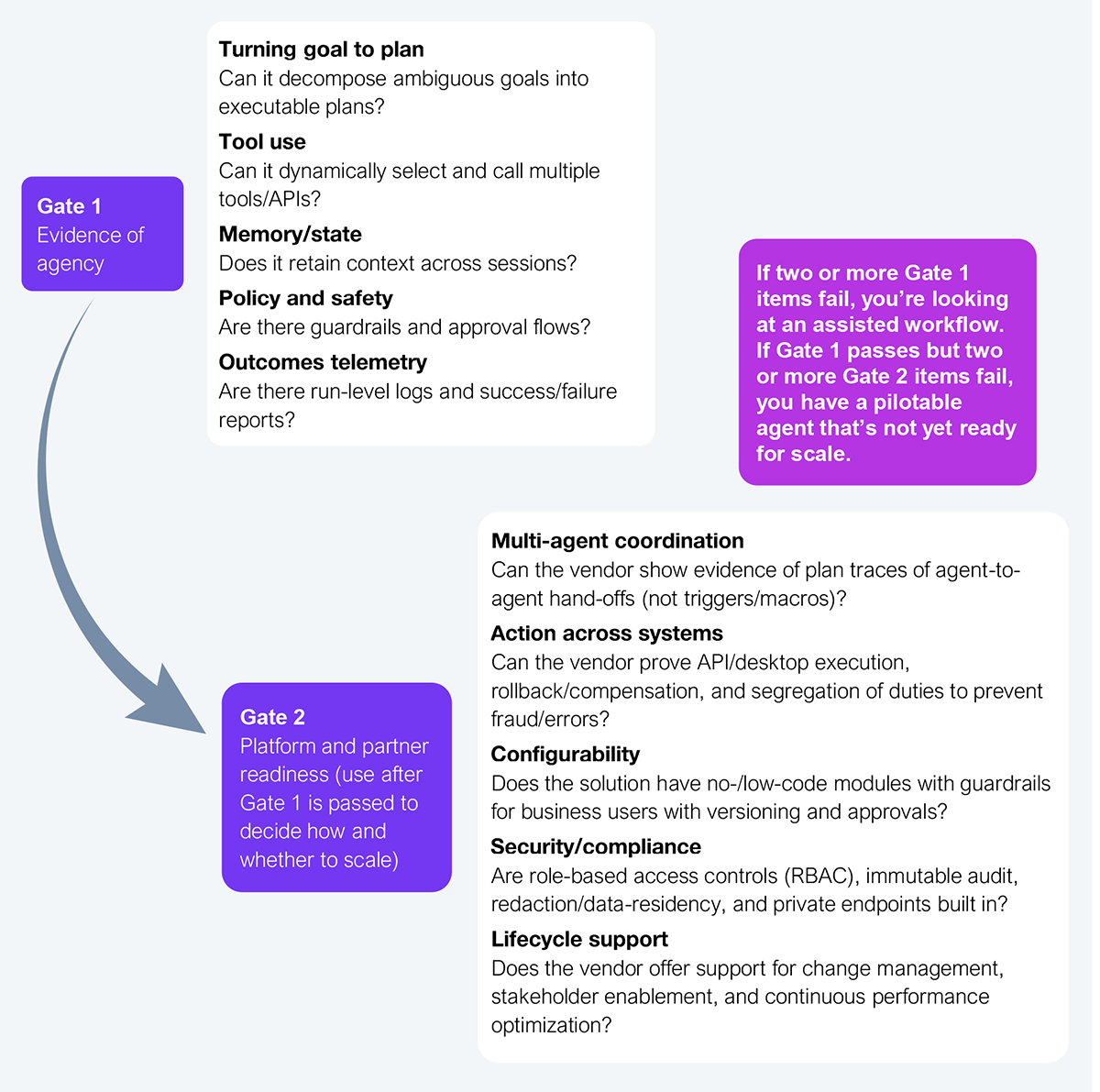
CIOs must demand verifiable proof—test results, audit logs, run traces—before accepting agentic AI claims at face value. HFS recommends using the two-gate Agentic Reality test to validate vendor claims (see Exhibit 3).
Source: HFS Research, 2025
To separate the wheat from the chaff, CIOs must follow these checkpoints to turn agent rhetoric into operating controls.
If a product can’t plan, pick tools across systems, remember context, and recover from failure, it’s a copilot. Label it, limit it, and buy useful assistance at assistant rates.
Register now for immediate access of HFS' research, data and forward looking trends.
Get StartedIf you don't have an account, Register here |
Register now for immediate access of HFS' research, data and forward looking trends.
Get Started
