The message at HfS’ Future of Operations Summit in Chicago earlier this month was loud and clear. When advancing toward Digital Transformation or the OneOffice, as we prefer to call it, clients don’t buy Robotic Process Automation (RPA), Artificial Intelligence (AI) or Blockchain off the shelf, rather they buy an outcome. To achieve those results, they need to integrate and orchestrate a broad, yet disparate set of capabilities. While clients are starting to get savvy in dealing with RPA deployments, they continue to struggle to make sense of the discussions around AI. They acknowledge that the Holy Grail of service delivery is the intersection of automation, analytics, and data as envisaged in HfS’ Triple-A Trifecta. But clients are still trying to understand the technology building blocks for AI as well as how data is interacting with all those innovations.
The scarcity of data scientists and talent that can deal with cognitive and AI challenges is one of the main inhibitors on the journey toward the OneOffice. Therefore, it is probably not surprising that providers like Amazon talk about democratizing AI while Salesforce hopes to evolve its Einstein platform into everyone’s data scientist. However, to progress toward AI-enabled outcomes that buyers want to see, the availability and accessibility of disparate and increasingly unstructured data sets is a challenge that often gets marginalized or even forgotten when discussing the innovations in service delivery subsumed under the Intelligent Automation moniker.
Without access to vast data sets, AI will remain narrow (See Exhibit 1), that is carrying out specific tasks such beating the world champion in chess or Go or more soberly recommend a song on Pandora, but that is the only (or at least main thing) a system does. Algorithms need more data than currently available to progress toward general AI with the goal to handle tasks from different areas and origins such as any intellectual task that a human being can handle. This is where IBM’s Watson Data Insights or Arago’s HIRO Knowledge Core comes in. They provide the data sets to reinforce the learning of the cutting-edge algorithms. Oracle’s Data Cloud is more confined to marketing while SAP’s Data Hub is focused on making data available across SAP environments. Lastly, with Amazon’s Public Datasets AWS hosts a variety of public data sets that anyone can access for free. Previously, large datasets such as satellite imagery or genomic data have required hours or days to locate, download, customize, and analyze. When data is made publicly available on AWS, anyone can analyze any volume of data without needing to download or store it themselves. These datasets can be analyzed using AWS compute and data analytics products.
Exhibit 1: The journey toward General AI is all about data
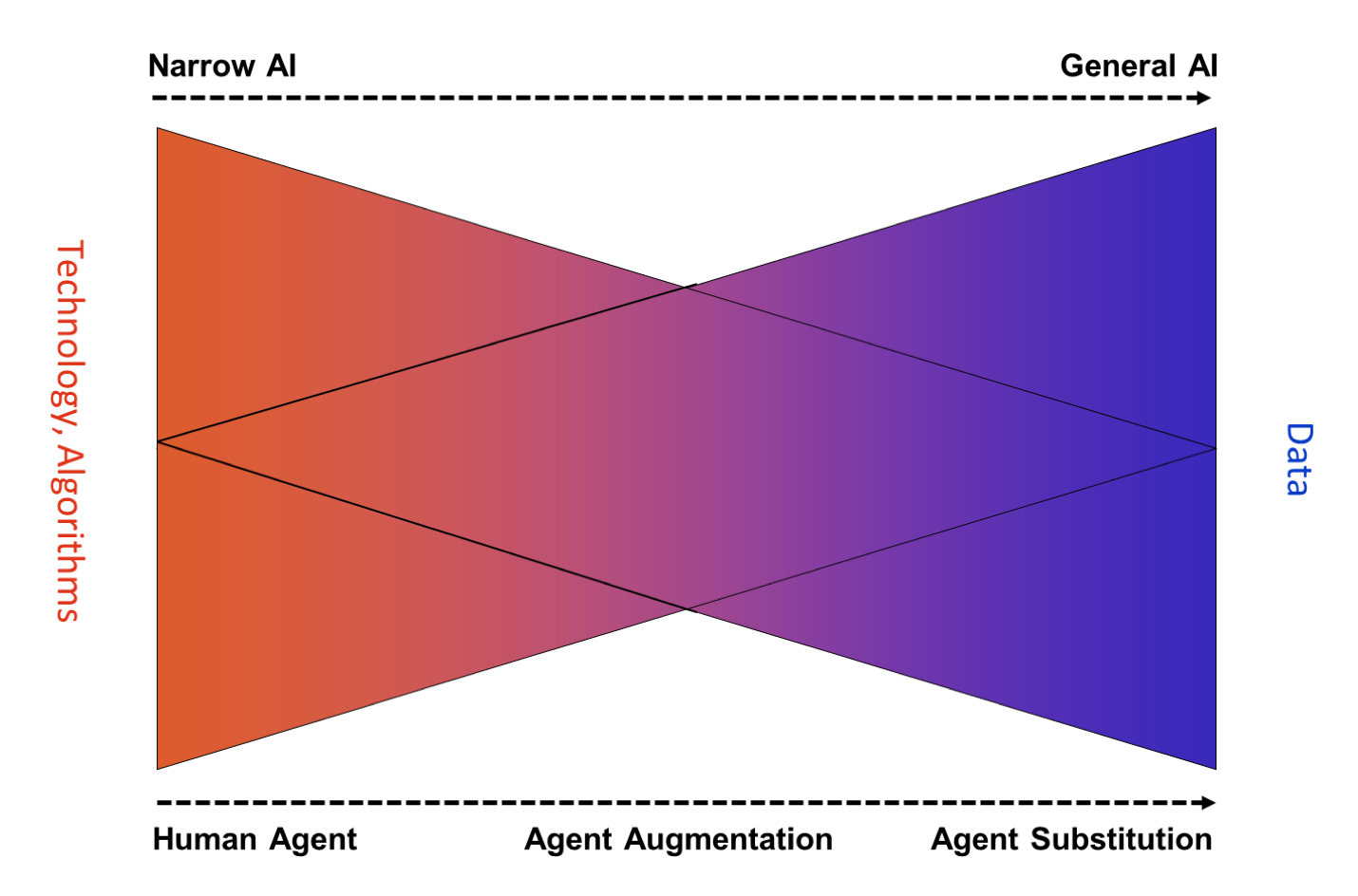
Source: HfS Research, 2017
Platforms such as SAP’s Leonardo, Oracle’s Adaptive Apps or Salesforce’s Einstein are integrating AI building blocks and data for specific use cases, thus help to overcome some of the constraints that we have called out. But to advance service delivery for instance for Shared Services Organizations, the data strategies have to deeper. At our conference in Chicago Lee Coulter from Ascension Health described the difference between Big Data projects and the need for integrating data on an industrial scale to progress toward the OneOffice aptly: “The perspective is moving from the rear mirror view to the windshield.” However, the data traditionally held in data warehouses cannot easily be leveraged for prescriptive analytics, utilizing Machine Learning. To get the data to answer the basic yet fundamental questions, what is about to happen and what should I do about it, organizations have to focus on the intersection of data engineering strategies and the work of data scientists.
|
“The perspective is moving from the rear mirror view to the windshield.” – Lee Coulter, CEO Shared Services, Ascension Health |
Lee’s as always astute observations culminated in the suggestion that Machine Learning requires “learnable” data. That is, data that is known to contribute to inference. And it is here where the hard work for service delivery organizations kicks in. Platforms can help to mitigate some of the challenges, but they can’t overcome the fundamental data challenges. The key message here is that a delivery organization has to evolve toward a data-centric mindset.
Exhibit 1 provides more color around what is a data-centric mindset. To progress toward autonomous processes that are at the heart of the OneOffice requires the access to increasingly unstructured data. Only when algorithms can learn from those vast data sets, we will inch further to the notion of General AI. In simple terms, less human interaction is required with more data that can be integrated and analyzed.
Bottom-line: Organizations must evaluate and invest in the interplay of technology innovation and data
While it might sound trite, data is becoming the new currency. But we don’t know yet who will become the custodian of data, be it IBM, Google, startups like Arago, be it a consortium or portfolio of providers. The quality of data rather than access to a set of technologies will be a key differentiator on the journey toward the OneOffice. This requires a shift in the mindset of buyers from being technology-centric to becoming data-centric. Suffice it to say this remains a challenge as the supply-side all too often tries to engage around technology rather than outcomes.
Recommendations for clients:
Register now for immediate access of HFS' research, data and forward looking trends.
Get StartedIf you don't have an account, Register here |
With the exception of our Horizons reports, most of our research is available for free on our website. Sign up for a free account and start realizing the power of insights now.
Our premium subscription gives enterprise clients access to our complete library of proprietary research, direct access to our industry analysts, and other benefits.
Contact us at [email protected] for more information on premium access.