The October AWS outage was more than a technical blip; it was a wake-up call for every CIO betting their AI workloads on hyperscaler resilience. As AI shifts from experimentation to execution, enterprises can no longer afford to make any assumptions about reliability. AWS, the foundation of much of today’s enterprise infrastructure, must prove it can deliver consistent, AI-ready performance before CIOs can trust it to run mission-critical workloads. If AWS doesn’t, its rivals will eat its lunch.
Within the next 24 months, a CIO’s AI platform choice will likely determine whether their firm’s cloud remains a strategic advantage or turns into a cost center. AWS is still the primary backbone of the enterprise cloud for many firms, but October’s US-EAST-1 outage exposes a systemic weakness: Many of AWS’s global control-plane systems are regionally concentrated.
AWS and its customers must make substantive changes and investments in their architecture and cloud service management. After all, the AWS cloud of the future will depend on how it creates value where AI compute resides, not just where infrastructure is located. The October 20, 2025, outage highlights to many CIOs that choosing cloud-based systems is no longer about feature checklists; it is about deliverable economics, predictable capacity, and enterprise trust.
A post-mortem review revealed that the October outage was caused by a DNS resolution failure affecting DynamoDB endpoints, which subsequently cascaded through IAM, EC2 autoscaling, and Lambda, impacting global workloads even when data was stored elsewhere. That pattern of cross-service fallout is the type of event that forces CIOs and boards to treat cloud reliability as a strategic risk rather than an operational issue.
Exhibit 1 illustrates this sequence of failures. To mitigate the risk of this happening again, enterprises must bake multi-region failover and dependency mapping into Tier-1 service level agreements, forcing hyperscalers to translate architectural promises into measurable commitments.
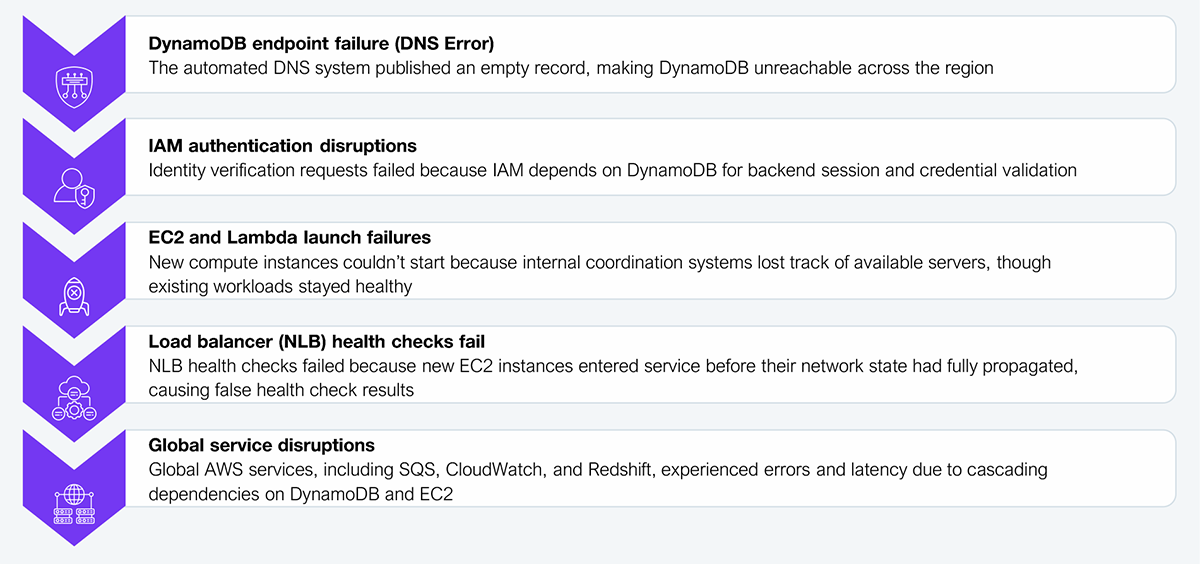
Source: HFS Research, 2025
The outage changed the conversation inside enterprise boardrooms. For CIOs, the focus extends well beyond uptime metrics. To ensure they have the resiliency they need, CIOs must quantify cloud dependency risk and understand where data resides, where control-plane services are deployed, and how quickly a DNS or IAM disruption can impact operations. Resilience is no longer purely a single-cloud concern. Enterprises are demanding interoperability across hybrid and multi-cloud environments, especially for data-heavy and AI-driven workloads. This creates additional architectural and operational complexities that cloud providers must strategically address to meet the evolving demands of enterprises.
AWS has built significant AI building blocks, including Trainium2 silicon and Trn2 instances, Bedrock as the foundation model platform, and Amazon Q for business assistants. On paper, Trainium2’s 4X performance positions AWS to compete on AI cost efficiency. However, that advantage has yet to translate into visible business outcomes or cost predictability for enterprises. Early feedback on Amazon Q’s rollout points to accuracy and workflow integration gaps, reinforcing the perception that AWS’s AI feels infrastructure-first, not outcome-first.
Meanwhile, AWS’s competitors are winning by transforming AI platforms into enterprise experiences, resulting in significant growth across hyperscaler platforms; however, AWS appears to be losing steam. Microsoft is leveraging an integrated stack, including Azure infrastructure, Azure OpenAI services, and Copilot, across Microsoft 365 to provide customers with a productized AI experience that spans from data to user workflow. Google’s Gemini and Vertex AI bring similar cohesion, blending developer flexibility with everyday Workspace integration. These are not fringe capabilities; they are the way many enterprises are currently experiencing AI.
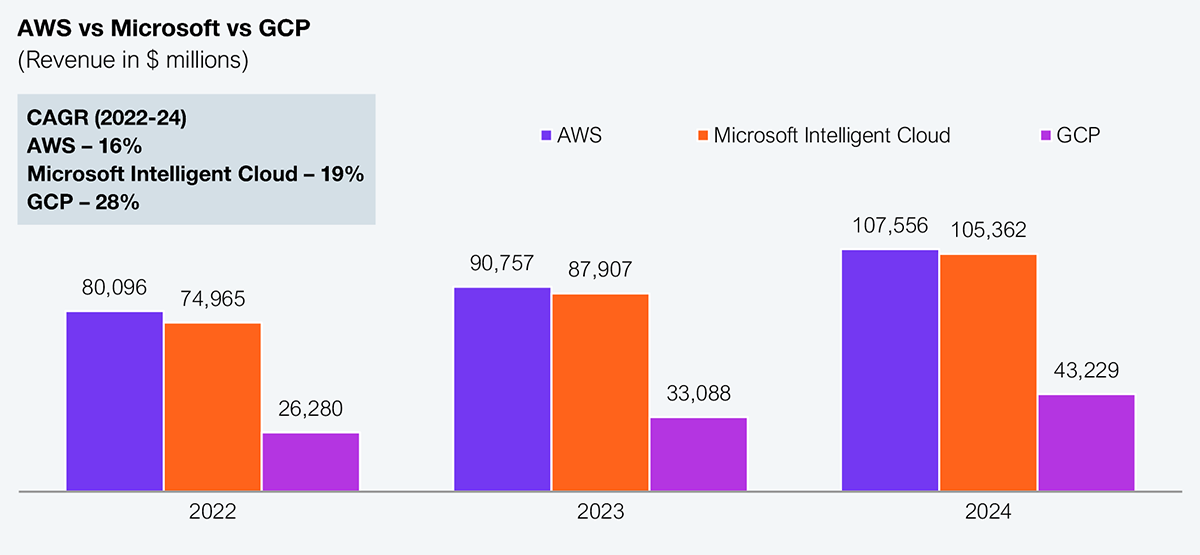
Note: Microsoft’s “Intelligent Cloud” is considered, which includes server products, cloud services, and enterprise services. Google Cloud includes GCP and Google Workspace offerings and other enterprise services. While not exact comparisons, they provide directional input
Source: Company annual reports
AWS’s challenge is less about capability and more about alignment. In short, the competition for enterprise attention is about who delivers trust and control at scale rather than who has better chips or models. AWS’s compute, data, and AI stack reflects great technical strength but still lacks the kind of governance and transparency enterprises expect.
Neo-clouds and GPU specialists are redefining the infrastructure game
GPU-first providers, such as CoreWeave, are winning large GPU-heavy contracts and accumulating backlogs, offering pure AI capacity that can be cheaper, closer, and faster to deploy for certain workloads. For enterprises training large models or deploying intensive inference workloads, these players introduce a new procurement variable, choice, and remove the burden of vendor lock-in. This will eventually reshape how CIOs think about cost, capacity, and risk diversification. AWS cannot treat these players as peripheral, and neither will enterprise buyers.
From control planes to confidence
The US-East-1 dependency remains AWS’s single most significant architectural liability. AWS must accelerate control-plane diversification and publish verifiable SLIs for regional independence and outage containment. Enterprises will only re-trust a provider that shows a verifiable plan and proof points.
From silicon claims to AI economics
Trainium2 and Graviton4 give AWS a theoretical efficiency edge, but enterprise buyers need proof. Independent benchmarks, customer total cost of ownership (TCO) studies, and real workload metrics must replace marketing claims.
From platform to product
Bedrock, SageMaker, and Amazon Q must be positioned and packaged as end-to-end products that solve business problems, not platform primitives that require lengthy integration projects. That means vertical reference architectures, named lighthouse customers with public metrics, and turn-key deployment bundles (data, model, governance, and runbook). Competitors are winning on integrated experiences, and AWS must match that cadence.
From capacity promises to binding capacity options
GPU scarcity is driving enterprises to hedge their investments across multiple providers. As AI workloads scale, enterprise contracts will increasingly require reserved and enforceable AI capacity. This will lead SLAs to cover factors like burst availability, scaling, and GPU substitutions. AWS will soon be required to offer contractual AI capacity guarantees, which will transform infrastructure availability into a key competitive differentiator.
From compliance checkboxes to productization of sovereignty
The European Sovereign Cloud needs to be more than just a brand. AWS must treat sovereignty as a strategic product category, not a defensive posture. AWS must deliver a product that includes localized control planes, independent auditability, and procurement-friendly commercial terms for public sector and regulated industries. That will blunt one of the primary reasons enterprises choose a multi-cloud approach. The next phase of enterprise cloud selection will hinge as much on digital jurisdiction as on compute economics.
The bigger picture is that the cloud market is becoming increasingly fragmented. Enterprises now face a choice between scale (hyperscalers) and specialization (neo-clouds). The next generation of cloud leadership will depend on the three pillars of trust in the AI era: provable resilience, transparent economics, and operational sovereignty, rather than just who runs the fastest GPU clusters.
Microsoft is turning AI adoption into a seamless enterprise experience. By embedding OpenAI models and Copilot into everyday productivity workflows, it reduces adoption friction and captures the “last mile” of AI value where users interact. Azure becomes the invisible engine for outcomes, not just compute.
Google, through Gemini and Vertex AI, is creating a closed feedback loop between model development, deployment, and productivity tools. Its integration with Workspace and developer environments shortens time-to-value, turning AI into an operational capability.
Specialist GPU clouds, such as CoreWeave, heavily funded by Nvidia, are commoditizing raw AI capacity, forcing hyperscalers to compete on price, latency, and contractual guarantees, not just the breadth of services.
As businesses continually bet on cloud, data, and AI to deliver and differentiate their services, AWS owes its customers immediate, measurable actions that will ensure trust, investment, and adoption:
AWS is not finished, but its leadership is being contested at the intersection of cloud and AI. Reliability failures, mixed early product signals for Q, and the rise of specialist GPU clouds have handed Microsoft, Google, and niche players a credible narrative: They deliver integrated, productized AI faster, with clearer economics.
AWS has unmatched scale and technical depth, and hence has all the assets to win, but that no longer guarantees trust. To stay the backbone of enterprise AI, it must move from engineering excellence in pieces to commercial certainty at scale. That means concrete proofs, published economics, a stronger control-plane architecture, and enterprise products that directly map to business outcomes.
Register now for immediate access of HFS' research, data and forward looking trends.
Get Started




If you don't have an account, Register here |
Register now for immediate access of HFS' research, data and forward looking trends.
Get Started