Process industries are crying out for advanced analytics, yet they stagger behind much of the manufacturing space on the journey toward Industry 4.0. Despite accounting for over 50% of its $35 trillion global output, process production that encompasses oil, steel, cement, and many other sectors is stuck in its old ways; meanwhile, “discrete manufacturing” sectors such as automotive or electronics have revolutionized. Process manufacturing leaders must embrace synthetic data to slipstream their analytics projects—a critical first step in keeping pace with their industry peers.
Poor historical data plagues the process industry and hampers its adoption of artificial intelligence (AI) and advanced analytics. Synthetic data has the potential to rip up the rule book, and the process industry is in dire need of it; profit margins squeeze the life out of the industry’s laggards—process optimization can mean make or break. Operational experience in combination with synthetic data, which is generated from smaller data sets, can help train more complex algorithms to drive two key use cases for analytics in the process industry: process optimization and predictive maintenance.
Process industry performance is a slave to fractional changes in pressures, temperatures, compositions, and flow rates; highly-integrated processes are crying out for analytical capabilities far beyond even what the most experienced engineer or operator can provide.
Tight margins on oil, metals, cement, and other process products mean that companies gaining the smallest percentage efficiency improvements can thrive. Despite this, optimization remains largely manual as most “automated process control” (APC) systems cannot account for the complexity and scale of cause-and-effect throughout an entire production plant.
Exhibit 1: Quandaries when analyzing a typical process
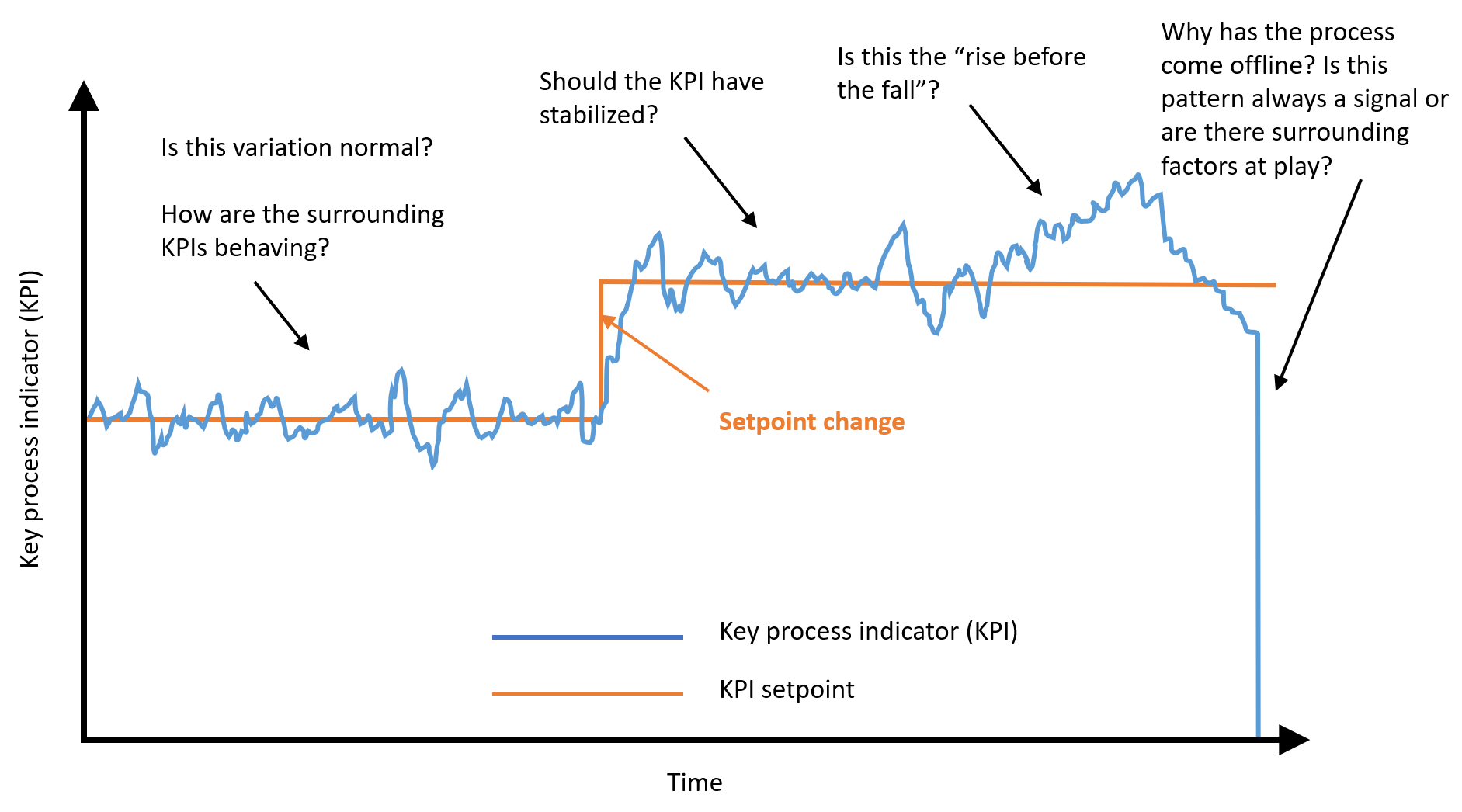 Source: HFS Research, 2019
Source: HFS Research, 2019
Vendors are selective—the digitally lagging process industry must clean up its data or risk becoming unserviceable
When AI vendors see process industries’ lagging digital standards, many won’t want to touch them with a barge pole for fear of going over budget or failing to disentangle their data. Poor historical data stemming from sensor inconsistencies and unplanned downtime means that even a manual analysis of data trends is difficult; engineers must often rely on their experience and gut instinct to decide what data is usable.
AI, in all its forms, can revolutionize data processing—going way beyond what humans can comprehend. However, algorithms are not the magic fairies many want. The algorithms that underpin AI require a level of sophistication and training that few are taking full advantage of. Despite analytics having the biggest potential performance impact in oil refining, digital technologies and capabilities are far down the list of investment priorities.
Synthetic data is created by algorithms that have been fed small samples of data, which in turn can be used to train more sophisticated algorithms. However, training algorithms on only “smooth-sailing” data is dangerous. Predictive maintenance to avoid unplanned process downtime (commonly caused by a process entering sub-optimal or dangerous conditions) is a key business driver for all manufacturing to develop advanced analytics capabilities. Algorithms must know what unusual conditions look like and be able to distinguish between sub-optimal operation that can be tweaked versus dangerous operation that requires rapid intervention.
The process industry needs AI and analytics with two distinct capabilities, working in tandem, taking over from one another when required:
As experienced as operators or engineers may be after decades on-site, one thing is indisputable: they’re only human. Advances in AI and analytics are at risk of going uncaptured in the process industry because of unstructured and inconsistent data. Manual analysis is possible, but it is severely limited by the extent to which humans can filter out periods of unexpected downtime or equipment malfunction.
When process industries build their analytics capabilities of the future, they must bring process engineers and operators into the design stage if there is any hope of training algorithms to analyze both real and synthetic data, while knowing when to switch between the two.
Process industries have so much to gain from advances in AI and analytics. Where margins and market prices squeeze the life out of producers, industries cannot miss opportunities to improve efficiency. But first, they must overcome poor historical data.
Two key drivers exist for AI and analytics in the process industry: driving down operating costs and improving predictive maintenance. Both are achievable, but the underpinning algorithms must be correctly designed. Synthetic data can produce data sets un-marred by sensor malfunctions and inconsistencies or unplanned process downtime; however, it produces sets of “ideal” data.
Two data sets are therefore required to create two sets of algorithms working side by side:
Creating these data sets will not be easy. But one key resource is available—experienced engineers and operators. They have manually optimized processes for decades, even in the face of bad data. In the design of analytics algorithms, they must be brought in to the discussion. Their experience cannot go to waste.
Register now for immediate access of HFS' research, data and forward looking trends.
Get StartedIf you don't have an account, Register here |
With the exception of our Horizons reports, most of our research is available for free on our website. Sign up for a free account and start realizing the power of insights now.
Our premium subscription gives enterprise clients access to our complete library of proprietary research, direct access to our industry analysts, and other benefits.
Contact us at [email protected] for more information on premium access.
