The news of Chris Cox—Chief Product Officer and Head of WhatsApp—departing Facebook one week after CEO Mark Zuckerberg published his privacy manifesto clearly points to some fundamental internal disagreements regarding Facebook’s recent announcements and policies on protecting user data privacy. In short, Zuckerberg’s declaration that the future of Facebook lays in “private communication” is a complete 180-degree flip from the foundation of Facebook’s entire growth to date, which is based on billions of users sharing their data publicly and allowing marketers to target them with advertisements.
The deeper issue stems from how Facebook employees have been directed—with Zuckerberg’s statement that his employees would focus on new criteria that included “making progress on the major social issues facing the internet and our company.” For example, Facebook has just claimed it removed 1.5 million videos of the tragic New Zealand terrorist attack in the first 24 hours. It blocked 1.2 million of them at upload, meaning users would not have seen them. Facebook has failed to disclose how many people had watched the remaining 300,000 videos. Despite their obvious attempts to have the public perceive they are successfully addressing the issue, it is still alarmingly clear that the likes of Facebook, Google (YouTube), and Twitter are struggling to keep up with the sheer speed of managing these vast social media channels.
The underlying issue is that the social tech giants already have the technology to get ahead of the privacy issues, but are clearly caught in a Catch-22 that is preventing them from taking the lead in ensuring data privacy. The bottom line is that their entire revenue models are tied implicitly to eyeballs on their sites, and making inherent changes to privacy may seriously impact their profits. There is no doubt that the major tech, social, and privacy issues are going to dominate the next round of sensitive political elections across the US and Europe. US presidential candidate Elizabeth Warren has already declared she will look to “break up Amazon, Facebook, and Google as they exert too much control over American lives. They’ve bulldozed competition, used our private information for profit, and tilted the playing field against everyone else.”
AI is a double-edged sword. On the one hand, it can generate quick insights from huge volumes of data, monitor and handle hazardous situations and environments, and free us from long hours of mundane work. But on the other hand, it needs fuel: data. As Exhibit 1 shows, in a recent HFS survey, more than 50% respondents indicated that they think their data is usable, maintainable, and sizable. Data that is technically usable may still trigger privacy concerns among individuals who have generated the data and hence own it.
Exhibit 1. Data being usable doesn’t mean the owners of the data are comfortable with all its potential usage
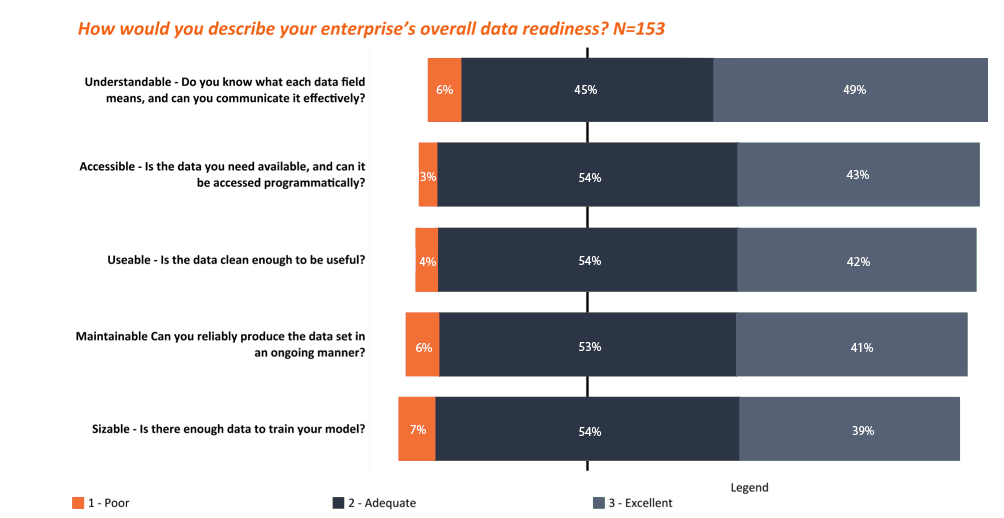
Source: HFS Research, “State of Machine Learning 2018”
The very ideas of data privacy and data being an intangible personal asset have evolved as technologies progressed and innovations made their way into mainstream society. An 1890 Harvard Law Review article by Warren and Brandeis on “The Right to Privacy” is a foundational piece that stills serves as a guiding document for several data privacy laws enacted by states around the world. The right to be “left alone” has been a fundamental human right, as articulated by Sir William Blackstone in his great work “Commentaries on the Laws of England” way back in 1753.
Privacy, however, is always a trade-off, as we have explained in an article on AI fatigue. For example, when we use Google Map to navigate, to find nearby friends, to locate a hospital, or to discover good places to eat or when we book an Uber, how will we avail ourselves of any of these services if we don’t share our locational information? Unfortunately, that same locational information that makes your life easier can also be potentially accessed by criminal hackers with malafide intent. It’s a choice that human users have to make: Do I trade security for convenience?
A “one size fits all” data privacy policy doesn’t work
The empirical practice is to get users to sign consent forms that have vast amounts of text running through multiple pages, signifying nothing. Omnipresent, overloaded consent agreements lead to consent fatigue, and unsuspecting users become victims.
Regulatorily as well as reputationally, enterprise AI leaders must frame dynamic and flexible data privacy policies and aim to design an intelligent “data trust orchestrator” to:
For example, where users are unwilling to provide access to usage of their data, developers should explore synthetic data generation and approximation techniques, such as Bayesian Program Synthesis, that focus on fast learning with minimal data.
Enterprise AI leaders entrusted to execute a privacy pivot to preemptively protect both their organizational reputation and their compliance to GDPR and data privacy laws of the land can anchor their data privacy initiatives for AI in these five approaches:
1. Take a flexible approach toward data protection. Adhering to regulatory requirements like anonymizing data and masking personally identifiable information (PII) as needed for GDPR may not be enough to build user confidence across the spectrum.
For example, 98% of Facebook’s revenue comes from advertising. It’s unacceptable to many people for a company to promote the effectiveness of targeted advertising by sharing clickstreams, posts, sentiment patterns, website access patterns, and buying behaviors of individuals, to increase addiction, stickiness, and compulsive purchase behavior.
2. Include and communicate with as many users as possible for feedback and views on their data privacy requirements and expectations, even if technical complexity increases. Let users visibly take control of their data and freely express their opinions and thoughts on what they think as a breach of trust on the usage of their data, and in which use cases they think it’s okay, for example the self-harm prevention module as described below.
In September 2018, Facebook launched an example of “affective computing”—emotion and sentiment processing through AI. Its contextually intelligent potential self-harm detection module uses the Random Forests technique on posts and comments to detect potentially high-risk scenarios.
3. Design and build a flexible, dynamic, intelligent data trust orchestrator that can not only implement current data privacy policies but can also discover and learn potentially new policies from user feedback and new training data corpus, in near real-time.
4. Design your major AI use cases technically covering two scenarios—a data-intensive scenario and a less-data-intensive one. A data-intensive scenario could cover when users and regulators have allowed a large corpus of user data to be accessed in procedural and legal scenarios, like E-KYC in banking and insurance. A less-data-intensive scenario could be where data is technically accessible, but the users or regulators have not okayed its usage to train models in certain AI solutions and use cases.
5. Build an AI skillset that factors in data-intensive ML skills and skills for data approximation, less-data scenarios, and synthetic data generation. Even in text-based processing alone, such as sentiment analysis or negative news classifier applications, there are different sets of algorithms such as Random Forests and XGBoost on good volumes of data; GANs to generate or simulate and estimate realistic data patterns; or special-purpose data generators, XML generators, multi-dimensional generators, and stream generators.
Read our report on synthetic data to find out more on this subject.
As we have highlighted, data privacy is dominating the narrative along public, private, corporate, and social agendas. There is no hiding from this as we develop our careers in this data-hungry world where we want both immediacy and privacy of information. Beyond regulatory compliance, taking a flexible, participative, aware, transparent, and dynamic approach to the data privacy policies regarding usage in AI use cases is imperative for success in AI adoption.
Register now for immediate access of HFS' research, data and forward looking trends.
Get StartedIf you don't have an account, Register here |
With the exception of our Horizons reports, most of our research is available for free on our website. Sign up for a free account and start realizing the power of insights now.
Our premium subscription gives enterprise clients access to our complete library of proprietary research, direct access to our industry analysts, and other benefits.
Contact us at [email protected] for more information on premium access.
